The Ultimate ZK-EVM Comparison Guide

A software engineer turned developer relations engineer in the web3 space, from Australia 🇦🇺.
All ZK-EVMs (Zero-knowledge Ethereum Virtual Machines) aim to achieve the same goal; make Ethereum more scalable and grow the adoption of web3.
As a developer, there are now several different options you have to create and deploy smart contracts onto a ZK-EVM, each with unique implementations, benefits, and drawbacks.
In this post, we'll cover the different kinds of ZK-EVMs as defined by Vitalik, the pros and cons of each, discuss which companies are working on them, and deploy smart contracts to each one.
Let's dive into it!
Recap: What Is A ZK-EVM?
If you're reading this and you aren't already familiar with zero-knowledge proofs or ZK-EVMs, I'd encourage you to read two of my previous posts linked below.
First, a basic understanding of ZK-EVMs:
If you want to go deeper, I also made a post covering how zero-knowledge proofs work, without any of the math:
TLDR: ZK-EVMs are Ethereum rollups that batch transactions together and post a "validity proof" of that batch back to the Ethereum blockchain + they're EVM-compatible, meaning you don't need specialized tools to work with them.
The EVM, Opcodes & Bytecode
The Ethereum Virtual Machine (EVM) is the runtime environment for smart contracts on Ethereum. Ethereum not only stores all accounts and balances similarly to Bitcoin but additionally stores what's called a "machine state".
The machine state is stored in a trie data structure, and changes from block to block after executing the transactions contained within that block.

The EVM is deterministic, meaning a set of instructions performed on any given state will result in the same new state every time. A simple analogy for this is to imagine a game of chess.
The chess board (Ethereum) has a large (in Ethereum, infinite) number of states the game can be in. The game has rules on what moves (transactions) can be performed, and restrictions on who can perform what actions (using accounts, signatures, etc.).
Just like Ethereum, players make moves (submit transactions), and the game (Ethereum) dictates what rules are allowed, and executes them, resulting in a new board (world) state after each move (block).
The Ethereum documentation describes this as a mathematical function:
Y(S, T)= S'2Given an old valid state
(S)and a new set of valid transactions(T), the Ethereum state transition functionY(S, T)produces a new valid output stateS'
High-Level Languages & Bytecode Compilation
As a developer on Ethereum, or any other EVM-compatible blockchain you're usually writing smart contracts in Solidity (although other languages like Vyper and Yul exist).
As with all other high-level languages, they're intended to be easily readable for humans, so we don't have to worry about the hard stuff like registers, memory addresses, and call stacks, and instead focus on usability.
However, machines don't understand this Solidity nonsense; the EVM included. The EVM understands bytecode, which is binary; machine-readable code.
The bytecode represents a series of EVM opcodes, each of which performs a specific operation in the EVM; sometimes these opcodes are concerned with stack operations like PUSH (add to the stack), or POP (remove from the stack) but also handles blockchain-specific operations like ADDRESS and BALANCE.
Each item is a 256-bit word, which was chosen for the ease of use with 256-bit cryptography (such as Keccak-256 hashes or secp256k1 signatures).
As developers, this means we need a way to convert our smart contract code from Solidity → Opcodes → Bytecode in order for it to be executable by the EVM.

Luckily for us, there are compilers that do this for us.
Compiling Smart Contracts
Let's look at an example. I've got a very basic smart contract written in Solidity:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.11;
contract Greeter {
// Internal state to the contract
string private greeting;
// Constructor - run when contract is deployed
constructor(string memory _greeting) {
greeting = _greeting;
}
// Read function (can be called without a transaction)
function greet() public view returns (string memory) {
return greeting;
}
// Write function (requires a transaction to be called)
function setGreeting(string memory _greeting) public {
greeting = _greeting;
emit GreetingChanged(_greeting);
}
event GreetingChanged(string newGreeting);
}
But, I have a problem. The EVM can't understand this Solidity! It needs bytecode... So, I'm going to use a compiler to help me out here; more specifically, for example, I can use the built-in compiler in the Remix IDE to help me.
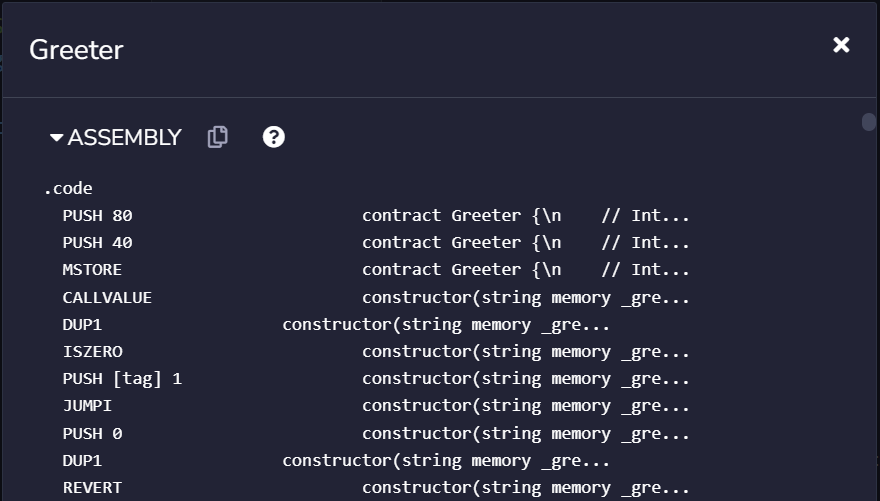
After I compile it, I can inspect the opcodes that get compiled, reflecting the contents of my smart contract.
Opcode:
I can also inspect the bytecode that gets compiled from those opcodes.
Bytecode:
60806040523480156200001157600080fd5b5060405162000c2938038062000c298339818101604052810190620000379190620001e3565b80600090816200004891906200047f565b505062000566565b6000604051905090565b600080fd5b600080fd5b600080fd5b600080fd5b6000601f19601f8301169050919050565b7f4e487b7100000000000000000000000000000000000000000000000000000000600052604160045260246000fd5b620000b9826200006e565b810181811067ffffffffffffffff82111715620000db57620000da6200007f565b5b80604052505050565b6000620000f062000050565b9050620000fe8282620000ae565b919050565b600067ffffffffffffffff8211156200012157620001206200007f565b5b6200012c826200006e565b9050602081019050919050565b60005b83811015620001595780820151818401526020810190506200013c565b60008484015250505050565b60006200017c620001768462000103565b620000e4565b9050828152602081018484840111156200019b576200019a62000069565b5b620001a884828562000139565b509392505050565b600082601f830112620001c857620001c762000064565b5b8151620001da84826020860162000165565b91505092915050565b600060208284031215620001fc57620001fb6200005a565b5b600082015167ffffffffffffffff8111156200021d576200021c6200005f565b5b6200022b84828501620001b0565b91505092915050565b600081519050919050565b7f4e487b7100000000000000000000000000000000000000000000000000000000600052602260045260246000fd5b600060028204905060018216806200028757607f821691505b6020821081036200029d576200029c6200023f565b5b50919050565b60008190508160005260206000209050919050565b60006020601f8301049050919050565b600082821b905092915050565b600060088302620003077fffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff82620002c8565b620003138683620002c8565b95508019841693508086168417925050509392505050565b6000819050919050565b6000819050919050565b6000620003606200035a62000354846200032b565b62000335565b6200032b565b9050919050565b6000819050919050565b6200037c836200033f565b620003946200038b8262000367565b848454620002d5565b825550505050565b600090565b620003ab6200039c565b620003b881848462000371565b505050565b5b81811015620003e057620003d4600082620003a1565b600181019050620003be565b5050565b601f8211156200042f57620003f981620002a3565b6200040484620002b8565b8101602085101562000414578190505b6200042c6200042385620002b8565b830182620003bd565b50505b505050565b600082821c905092915050565b6000620004546000198460080262000434565b1980831691505092915050565b60006200046f838362000441565b9150826002028217905092915050565b6200048a8262000234565b67ffffffffffffffff811115620004a657620004a56200007f565b5b620004b282546200026e565b620004bf828285620003e4565b600060209050601f831160018114620004f75760008415620004e2578287015190505b620004ee858262000461565b8655506200055e565b601f1984166200050786620002a3565b60005b8281101562000531578489015182556001820191506020850194506020810190506200050a565b868310156200055157848901516200054d601f89168262000441565b8355505b6001600288020188555050505b505050505050565b6106b380620005766000396000f3fe608060405234801561001057600080fd5b50600436106100365760003560e01c8063a41368621461003b578063cfae321714610057575b600080fd5b610055600480360381019061005091906102ab565b610075565b005b61005f6100bf565b60405161006c9190610373565b60405180910390f35b806000908161008491906105ab565b507f58c1144814f1df01a80f7347f945437a37cd818e027f87b0ade6db623ec41b57816040516100b49190610373565b60405180910390a150565b6060600080546100ce906103c4565b80601f01602080910402602001604051908101604052809291908181526020018280546100fa906103c4565b80156101475780601f1061011c57610100808354040283529160200191610147565b820191906000526020600020905b81548152906001019060200180831161012a57829003601f168201915b5050505050905090565b6000604051905090565b600080fd5b600080fd5b600080fd5b600080fd5b6000601f19601f8301169050919050565b7f4e487b7100000000000000000000000000000000000000000000000000000000600052604160045260246000fd5b6101b88261016f565b810181811067ffffffffffffffff821117156101d7576101d6610180565b5b80604052505050565b60006101ea610151565b90506101f682826101af565b919050565b600067ffffffffffffffff82111561021657610215610180565b5b61021f8261016f565b9050602081019050919050565b82818337600083830152505050565b600061024e610249846101fb565b6101e0565b90508281526020810184848401111561026a5761026961016a565b5b61027584828561022c565b509392505050565b600082601f83011261029257610291610165565b5b81356102a284826020860161023b565b91505092915050565b6000602082840312156102c1576102c061015b565b5b600082013567ffffffffffffffff8111156102df576102de610160565b5b6102eb8482850161027d565b91505092915050565b600081519050919050565b600082825260208201905092915050565b60005b8381101561032e578082015181840152602081019050610313565b60008484015250505050565b6000610345826102f4565b61034f81856102ff565b935061035f818560208601610310565b6103688161016f565b840191505092915050565b6000602082019050818103600083015261038d818461033a565b905092915050565b7f4e487b7100000000000000000000000000000000000000000000000000000000600052602260045260246000fd5b600060028204905060018216806103dc57607f821691505b6020821081036103ef576103ee610395565b5b50919050565b60008190508160005260206000209050919050565b60006020601f8301049050919050565b600082821b905092915050565b6000600883026104577fffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff8261041a565b610461868361041a565b95508019841693508086168417925050509392505050565b6000819050919050565b6000819050919050565b60006104a86104a361049e84610479565b610483565b610479565b9050919050565b6000819050919050565b6104c28361048d565b6104d66104ce826104af565b848454610427565b825550505050565b600090565b6104eb6104de565b6104f68184846104b9565b505050565b5b8181101561051a5761050f6000826104e3565b6001810190506104fc565b5050565b601f82111561055f57610530816103f5565b6105398461040a565b81016020851015610548578190505b61055c6105548561040a565b8301826104fb565b50505b505050565b600082821c905092915050565b600061058260001984600802610564565b1980831691505092915050565b600061059b8383610571565b9150826002028217905092915050565b6105b4826102f4565b67ffffffffffffffff8111156105cd576105cc610180565b5b6105d782546103c4565b6105e282828561051e565b600060209050601f8311600181146106155760008415610603578287015190505b61060d858261058f565b865550610675565b601f198416610623866103f5565b60005b8281101561064b57848901518255600182019150602085019450602081019050610626565b868310156106685784890151610664601f891682610571565b8355505b6001600288020188555050505b50505050505056fea2646970667358221220a1f816fe7c07bf6a147b15ff4e1b591d0b43aca9fc57c8ddaecce27d5fe6f5fa64736f6c63430008120033
The final bytecode you see there is what would be understood by the EVM. So you can imagine why developers want to use high-level languages rather than write the bytecode themselves.
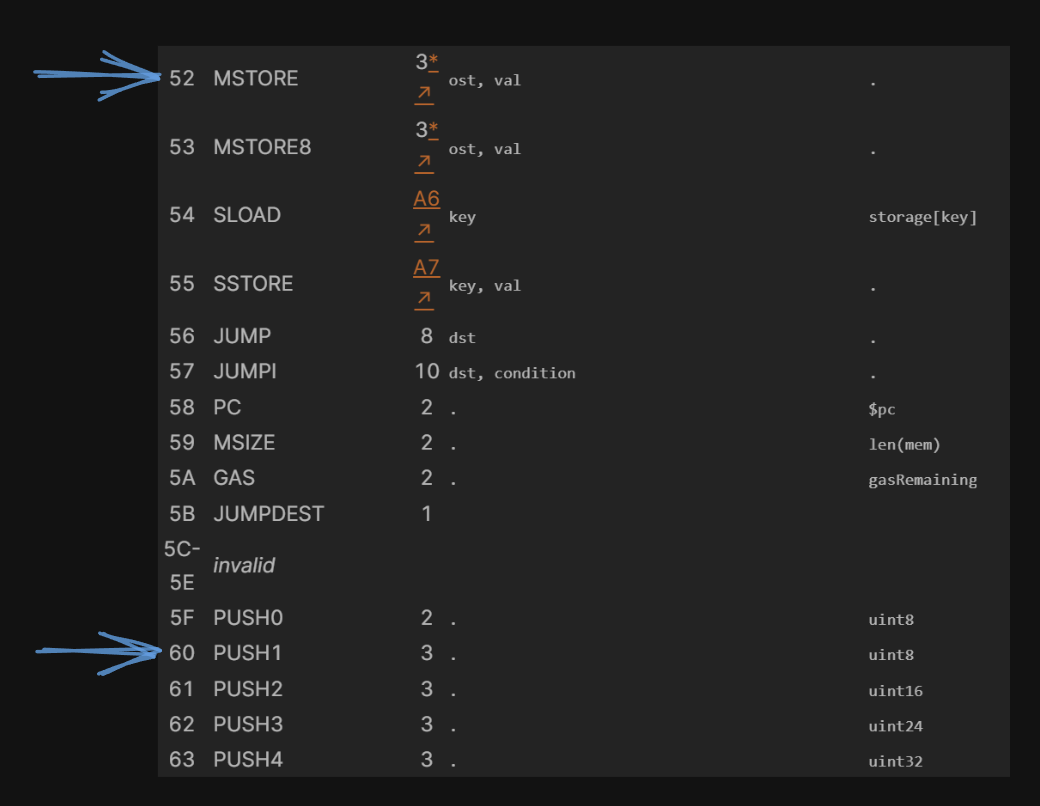
What we can do now is actually match up exactly what's happening in the bytecode to the opcodes. Let's take a look at the first three opcodes, PUSH 80, PUSH 40, and MSTORE.
I've matched up the first 10 hexadecimal values of the byte code to the first 3 opcodes we see below:

PUSH 80/6080: Pushes the value 80 (hexadecimal) onto the stack.PUSH 40/6040: Pushes the value 40 (hexadecimal) onto the stack.MSTORE/ 52: Stores the second stack item (40) at the memory location specified by the first stack item (80).
We can do this matching process because Ethereum documents each opcode corresponding to its bytecode value:
Why do Opcodes or the EVM Matter?
The challenge of building an EVM-compatible rollup is that Ethereum was not originally designed around ZK-friendliness, so there are many parts of the Ethereum protocol that take a large amount of computation to ZK-prove.
Specific opcodes executed by an EVM are more "ZK-unfriendly" than others, and this had led to variance in the level of EVM-compatibility companies have chosen to adopt in their ZK-EVM products.
For example, some have opted for full equivalency for every EVM opcode, some have slight modifications to some opcodes, and some actually embrace producing completely different bytecode while maintaining high-level-language equivalence.
Below, I'll explore the different approaches each ZK-EVM has made and the tradeoffs each of them makes between performance (how fast they can generate ZK proofs) and their level of EVM compatibility.
Different Kinds of ZK-EVMs
Vitalik made a blog post in August 2022 categorizing ZK-EVMs into four (and a half) different categories, titled "The different kinds of zkEVMs". I'll be summarising this information below, but I'd recommend reading the full post too.
In the post, Vitalik charts the different types according to their EVM compatibility and ZK-proof generation times (performance). View original image:

To simplify this, in my opinion, we can place ZK-EVMs on a single line:
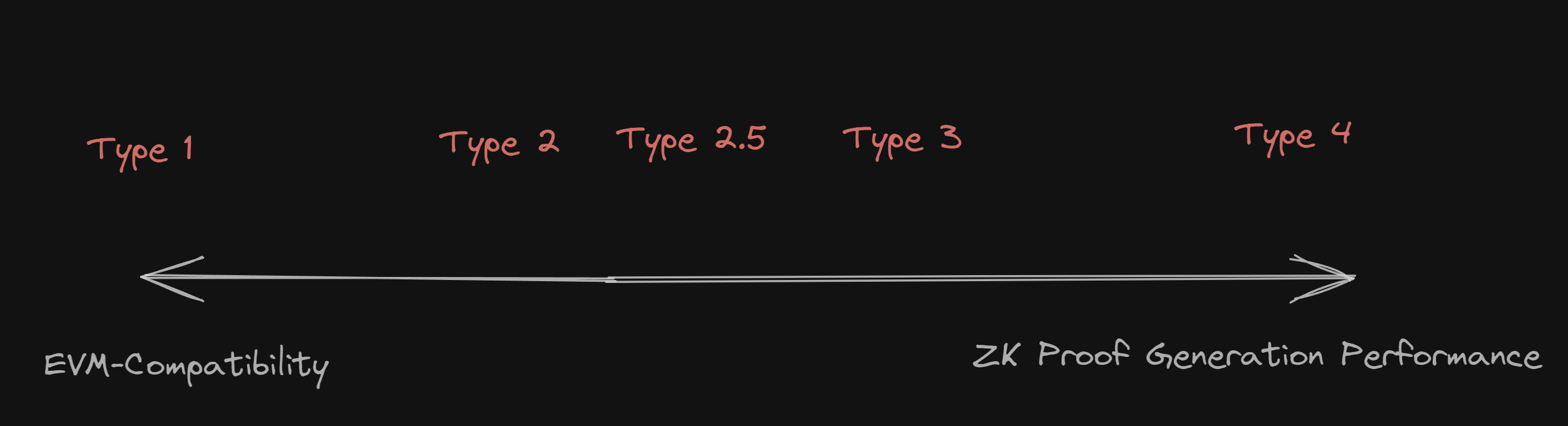
According to Vitalik, ZK-EVMs come in 4.5 different categorizations:
Type 1: Fully Ethereum equivalent, i.e. they do not change any part of the Ethereum system to make it easier to generate proofs. ZK proofs take several hours to generate in this kind of system.
Type 2: Fully EVM-equivalent, but changes some different internal representations like how they store the state of the chain, for the purpose of improving ZK-proof generation times.
Type 2.5: Fully EVM-equivalent, except they increase the gas costs of some operations to "significantly improve worst-case prover times".
Type 3: Almost EVM-equivalent ZK-EVMs make sacrifices in exact equivalence to further enhance prover times and simplify EVM development.
Type 4: High-level language equivalent ZK-EVMs compile smart contract source code written in a high-level language to a ZK-SNARK-friendly language, resulting in faster prover times but potentially introducing incompatibilities and limitations.
Companies Building ZK-EVMs
Below, I'll show you the current landscape of all the different types of ZK-EVMs being built by various companies; including Taiko, Linea, Polygon, Scroll, and zkSync (plus a special bonus guest). I'll also be trying out each of the ZK-EVMs from a developer perspective.
For a fair test, I'll be using EVM Kit as my starting point for each; a full-stack boilerplate setup for creating web3 applications (learn more), including both smart contracts and web apps.
From a new EVM Kit project, I'll first deploy a basic smart contract written in Solidity & built in a Hardhat environment to each of the different ZK-EVMs we have explored to review the developer experience of writing smart contracts.
Second, I'll deploy an NFT collection smart contract to each, and mint some NFTs to see the gas price of interacting with common EIP standards on each chain as well.
We'll go through each in order of their "type", starting from type 1 and working our way up to type 4.
First up, we have Taiko at type 1.
Taiko
Note: Taiko is currently in the testnet phase.
Taiko is a type 1 ZK-EVM, meaning it replicates all of Ethereum's behaviour exactly the same, using the same hash functions, gas prices, encryption algorithms, etc. except Taiko currently handles two Ethereum Improvement Proposals differently.
The primary benefits of this architecture are:
The development process is identical to using Ethereum.
Taiko re-uses a lot of Ethereum infrastructure such as the node client software, making it very familiar to Ethereum users.
There are no changes to hash functions or gas costs.
Taiko's approach is to fully optimize for EVM-equivalency, which comes at the cost of a large time to generate ZK proofs that get posted back to Ethereum.
The Taiko L2 uses the same rules of Ethereum to determine the new state of the rollup; immediately and deterministically after a block is proposed.
The drawback to this is slow ZK proof generation time, which is required to give certainty about the execution that happened on the rollup to bridges; meaning you won't be able to bridge funds back to Ethereum L1 until that proof is generated.
Deploying to Taiko ZK-EVM (Testnet)
Since Taiko has not released their mainnet at the time of writing this, I'll be using the "Taiko Alpha-3 Testnet" throughout this process. First, I got myself some testnet funds from the Sepolia Faucet and sent funds over to Taiko using Taiko's Bridge:

Once I'm across the bridge, the development process is identical to using Ethereum. The only change I make is to transform my RPC from an Ethereum RPC to the Taiko RPC. Below is the information about the chain ID and RPC I used for this process:
| Chain ID | RPC |
| 167005 | https://taiko-alpha-3-testnet.rpc.thirdweb.com |
I was easily able to deploy my basic Solidity smart contract and perform both read and write operations on it as seen from the Taiko block explorer:

The process of deploying an NFT collection and minting my first Taiko NFT was also seamless, and worked exactly as I'd expect when working with Ethereum:
As I mentioned previously, the drawback of Taiko is that the ZK proof generation process is very lengthy, which means I am unable to bridge my ETH back to Ethereum L1 for several hours:
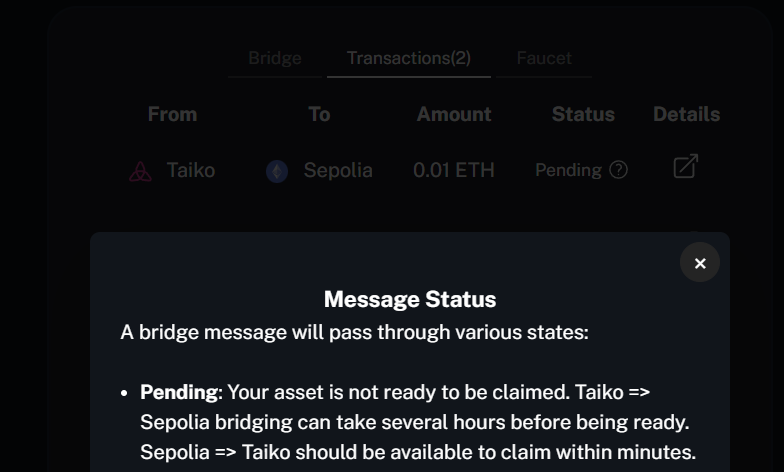
Your asset [my ETH] is not ready to be claimed. Taiko => Sepolia bridging can take several hours before being ready.
Below is the summary of my interactions with Taiko:
| Contract Interaction | Gas Fee (in ETH) | Gas Fee (USD) |
| Deploy Greeter Solidity smart contract | 0.000413119500275413 | $0.78 |
| Run "setGreeting" function | 0.00004744500003163 | $0.089 |
| Deploy NFT Collection (via proxy) | 0.001124796000749864 | $2.12 |
| Mint NFT | 0.00030571500020381 | $0.58 |
| Bridge funds back to ETH L1 | 0.000194796000129864 | $0.37 |
Keep in mind, these were all on Taiko's testnet and these numbers will be different than when Taiko launches their mainnet in the future.
Linea (Consensys ZK-EVM)
Note: Linea is in the process of releasing their mainnet later this month (July 2023)!
Linea's original announcement planned to release a type 2 ZK-EVM, however, their current release is a type 3 ZK-EVM working towards a type 2. As outlined in their risk disclosure documentation, Linea does not currently prove all EVM opcodes:
The validity proofs used to verify the computation of Linea batches do not prove 100% of EVM opcodes and precompiles
In addition, their documentation states the "proofs of computation for all EVM opcodes and precompiles" will come in phase 1 of their improvements as outlined in their roadmap:
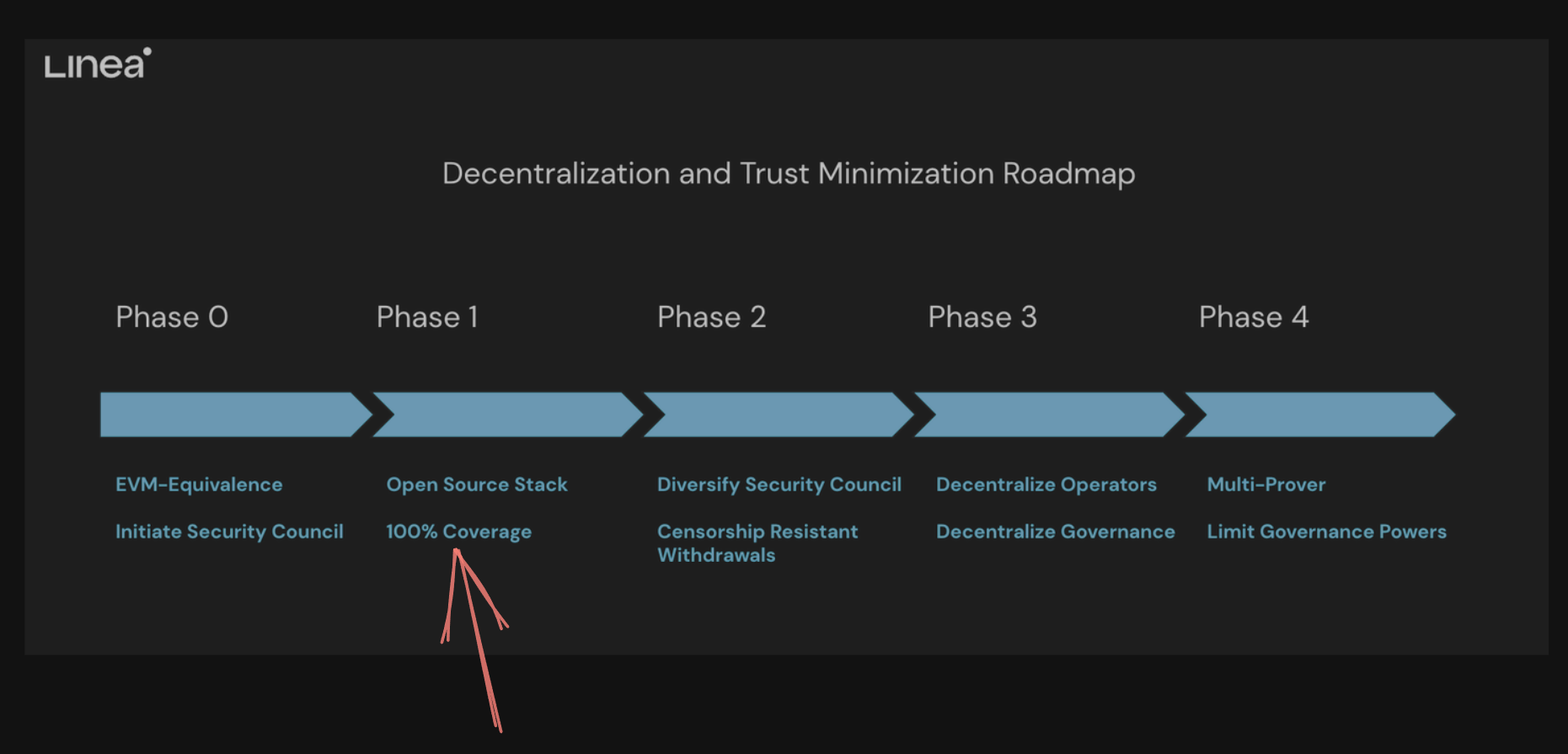
Linea also deviates from Ethereum in how it represents the state of the chain. For instance, keccak, a hashing function used by Ethereum has been changed for a more ZK-friendly alternative. Despite this internal difference, you're deploying the same smart contract bytecode to Linea that you would deploy if you were using Ethereum.
Deploying to Linea (Testnet)
Once I secured myself some Goerli testnet ETH (which was a slight mission), I headed over to the Linea bridge to bridge ETH to the Linea testnet.
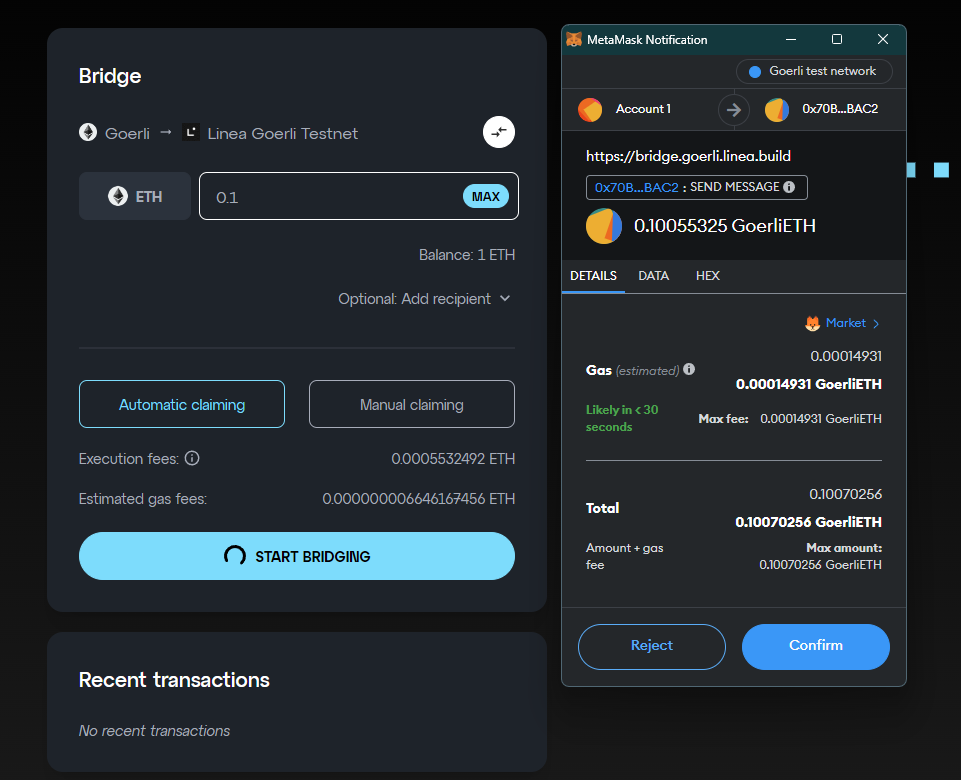
Once I successfully bridge my funds across, the development process is the same as Ethereum. Everything worked as expected with my Greeter smart contract:
And I was easily able to deploy the NFT collection and mint my first Linea NFT:
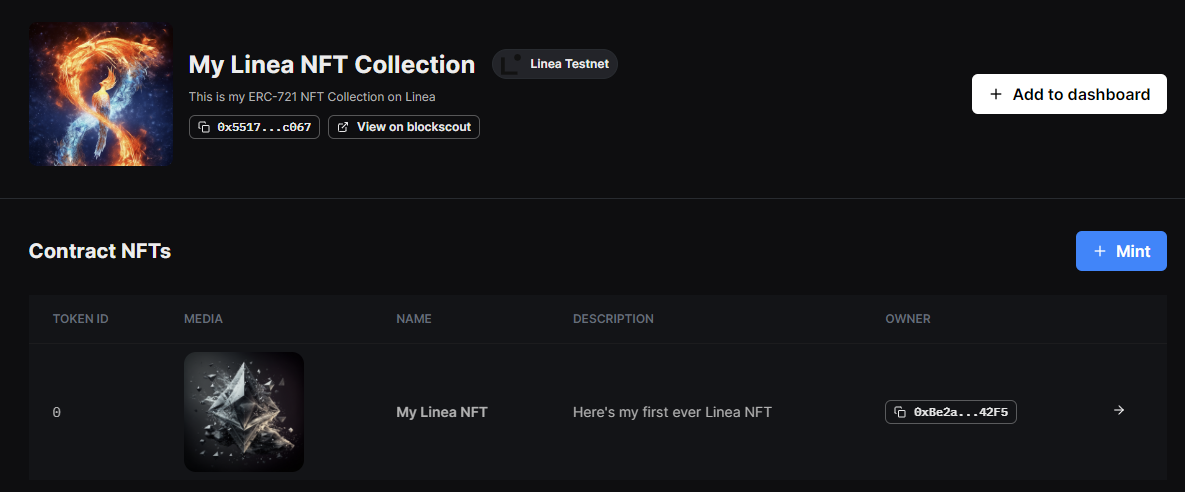
The bridge UI from Linea isn't currently available, but you can call the sendMessage function on their bridge smart contract directly. According to the Linea documentation, the bridging of ETH from L2 back to L1 takes ~15 minutes, but it took several hours during my testing.
Below is the summary of my interactions with Linea:
| Contract Interaction | Gas Fee (in ETH) | Gas Fee (USD) |
| Deploy Greeter Solidity smart contract | 0.000466914075602163 | $0.87 |
| Run "setGreeting" function | 0.000053601071759034 | $0.10 |
| Deploy NFT Collection (via proxy) | 0.001233567189763232 | $2.31 |
| Mint NFT | 0.000096778500451633 | $0.61 |
| Bridge funds back to ETH L1 | 0.000096778500451633 | $0.18 |
These were all very similar prices to Taiko; but again, are testnet values!
Polygon zkEVM
Disclaimer: At the time of writing this, I currently work at Polygon Labs. There may be some unconscious bias for this reason.
Polygon zkEVM is currently a type 3 ZK-EVM, with a small number of changes required before transforming into a type 2 ZK-EVM. You can view the opcodes, precompiled contracts, and other minor differences Polygon zkEVM transparently lists in the documentation that are different from the EVM's behaviour.
With these tradeoffs in equivalency to the EVM's behaviour, Polygon zkEVM is able to generate and post ZK proofs in just a few minutes; allowing you to bridge your funds back to Ethereum L1 in around ~30 minutes after interacting with the zkEVM.
With Polygon zkEVM, you're deploying the same bytecode as you would with Ethereum, however, the interpretation process of this bytecode is slightly different.
EVM Bytecodes are interpreted using a zero-knowledge Assembly language (zkASM), specially developed by the Polygon zkEVM team. In Vitalik's blog post, he mentions this:
Polygon has a unique design where they are ZK-verifying their own internal language called zkASM, and they interpret ZK-EVM code using the zkASM implementation. Despite this implementation detail, I would still call this a genuine Type 3 ZK-EVM; it can still verify EVM code, it just uses some different internal logic to do it.
The polygon engineering team has also stated they'll complete the remaining precompiles to become type 2 in addition to improving the proof generation & withdrawal times very soon.
Deploying to Polygon zkEVM
Polygon zkEVM mainnet beta launched in March 2023, so I'll be using mainnet funds for this process. First, I used the Polygon bridge to ship my funds across to the zkEVM. The gas fee for this process was around $5 USD and took ~5 minutes for the funds to arrive on the L2.

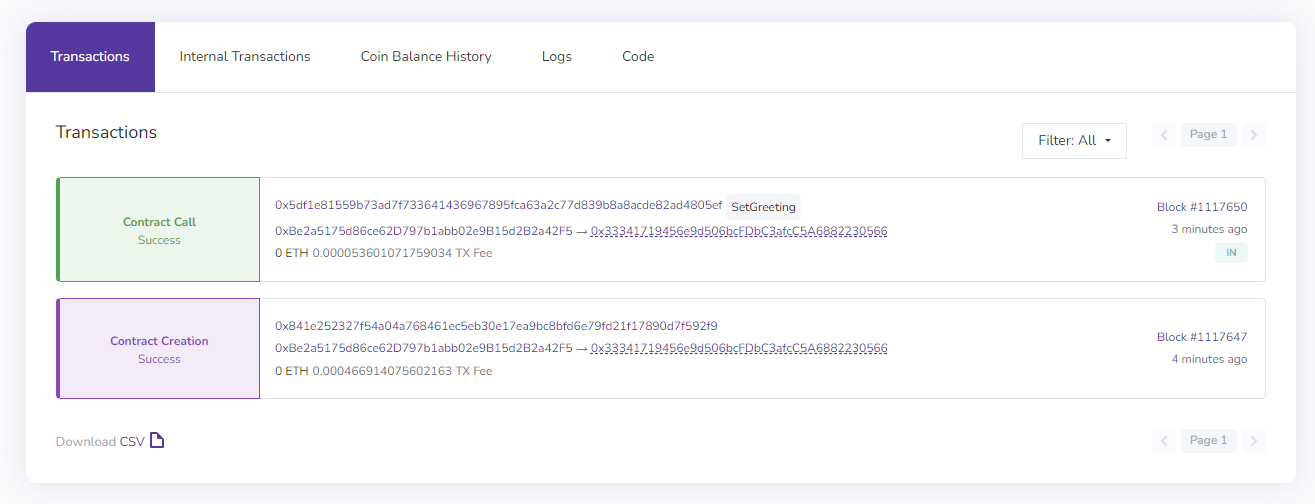
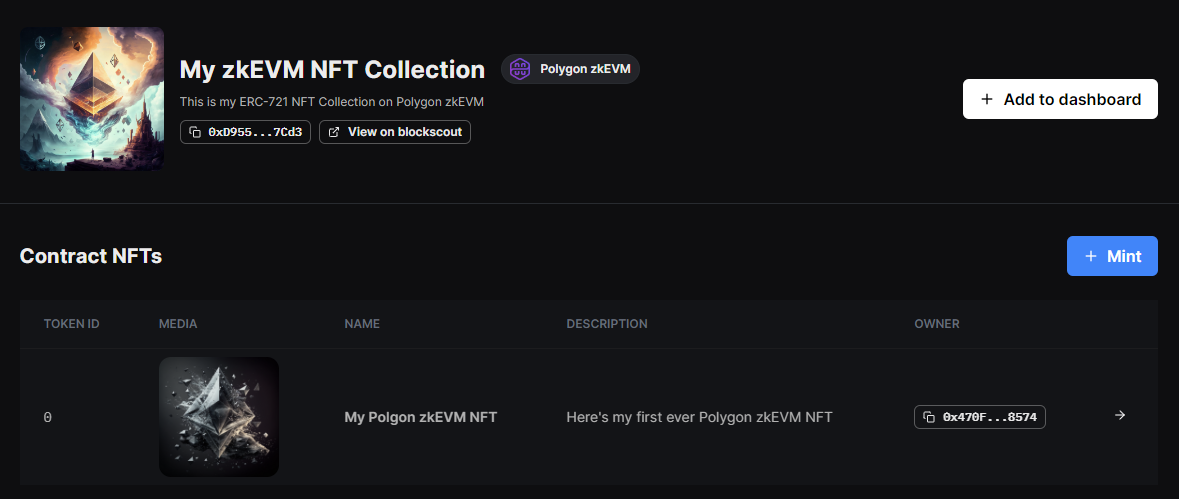
Just like the previous two chains, it's seamless and behaves as I'd expect Ethereum to. I was easily able to deploy my Greeter smart contract and call the functions on it as well as deploy an NFT Collection & mint an NFT:
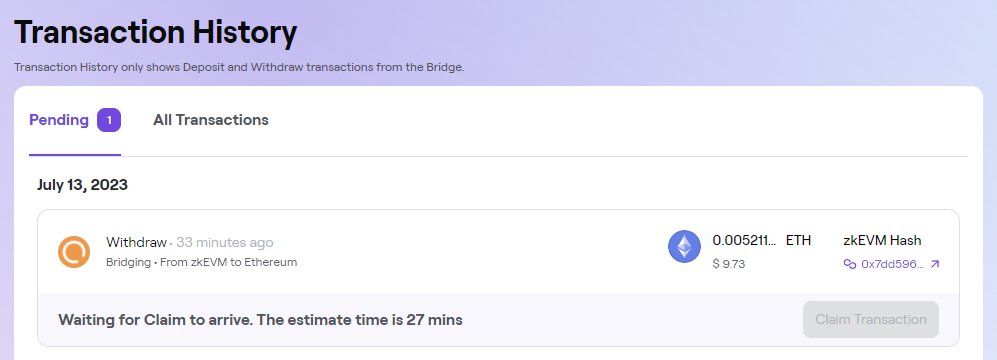
The bridging process back to Ethereum L1 took ~60 minutes and was another $5 to claim my funds back into Ethereum mainnet.
If you're looking to build on the Polygon zkEVM, consider checking out my guide below taking you through the full process in less than 10 minutes:
Scroll
Note: Scroll is currently in the testnet phase.
Similar to Polygon zkEVM, Scroll is currently a type 3 ZK-EVM working towards being a type 2, with transparent documentation on the opcodes, precompiles, and other differences from Ethereum defined in their documentation. The scroll docs outline:
For the average Solidity developer, these details won't affect your development experience.
On the Scroll blog, they have also listed the exact work remaining to release their mainnet - see Scroll zkEVM next steps.
Deploying to Scroll
Just like the previous chains we've explored so far, Scroll is able to execute the same native bytecode that you would deploy to Ethereum, meaning there's no change in the development process.
I'm easily able to bridge funds to the Scroll testnet via their bridge UI:
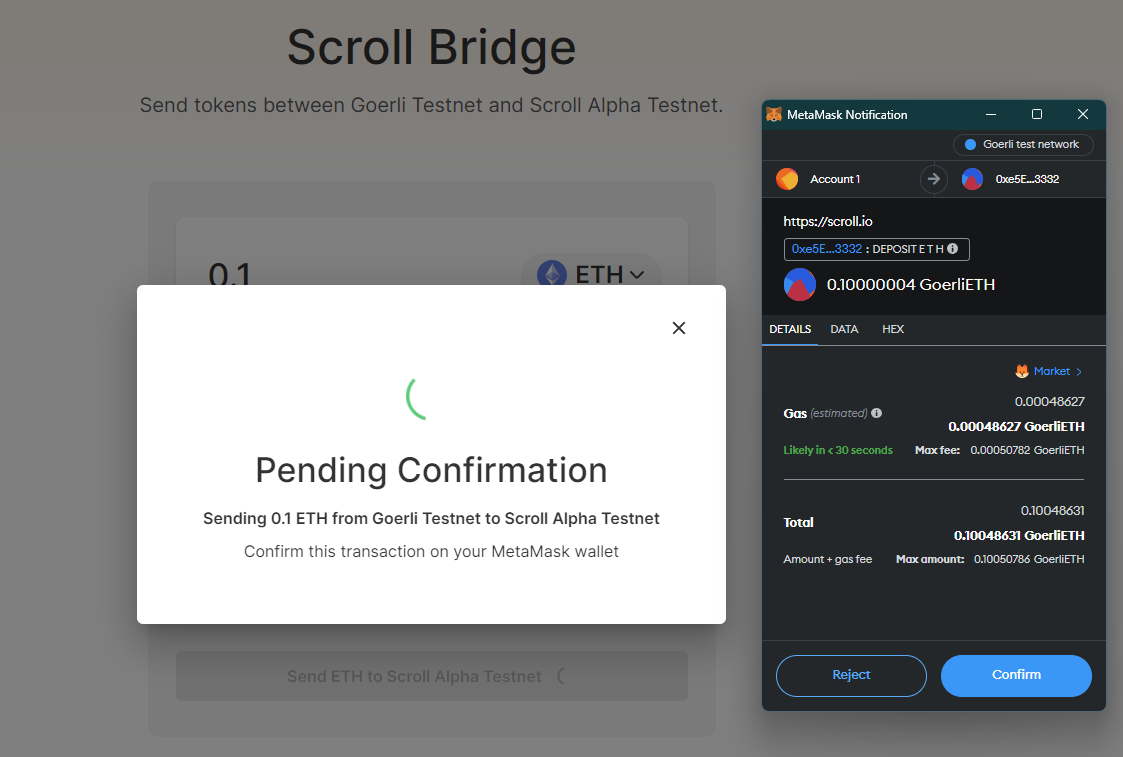
The estimated time to bridge funds to the L2 is between 8-14 minutes, and it took 10 minutes for me to be able to use them on the L2.
Everything acts the same way as I'd expect Ethereum to, and I was easily able to deploy my Greeter smart contract and my NFT collection again:
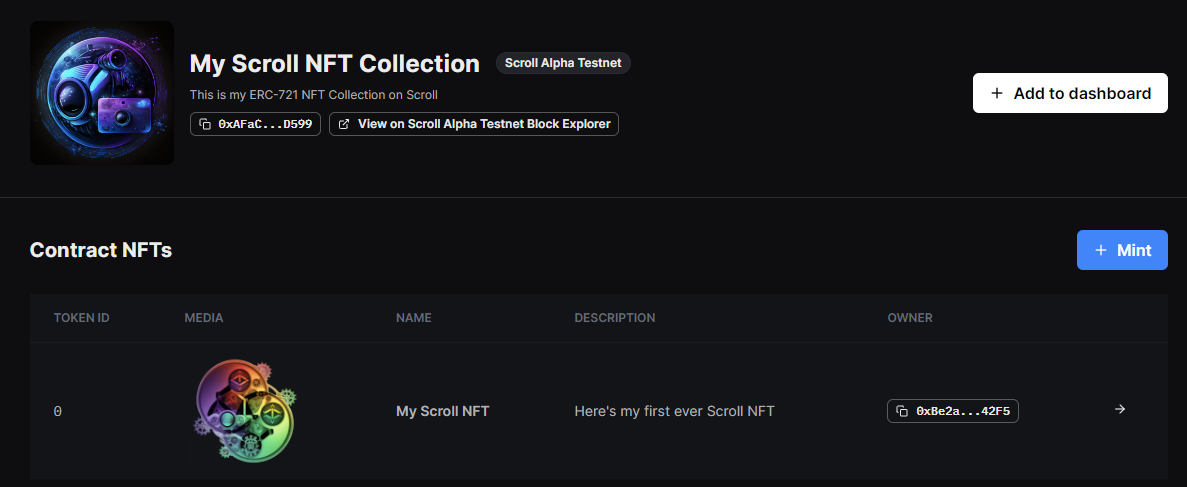
Bridging funds back to Ethereum L1 is estimated to take between 10 minutes to a few hours according to the Scroll documentation (unfortunately I missed exactly how long it took in my case).
Below is the summary of my transactions on the Scroll testnet. During my testing, the gas fees seemed to be significantly cheaper than the previous chains we explored, although I'm not sure of the exact reason for why this was the case:
| Contract Interaction | Gas Fee (in ETH) | Gas Fee (USD) |
| Deploy Greeter Solidity smart contract | 0.000000275329 | $0.00051 |
| Run "setGreeting" function | 0.000000031618 | $0.000059 |
| Deploy NFT Collection (via proxy) | 0.000000749896 | $0.0014 |
| Mint NFT | 0.00000020381 | $0.00038 |
| Bridge funds back to ETH L1 | 0.000000261872 | $0.00049 |
zkSync Era
zkSync Era is a type 4 ZK-EVM, and the experience is quite different from the other products we've explored so far.
Era embraces the fact that the smart contract bytecode that gets deployed for their zkEVM is not the same as Ethereum; and this large difference enables their product to have unique offerings, such as native account abstraction.
These base changes in capability come with differences in developer experience, but as Vitalik defined; still allows you to work with the same high-level languages such as Solidity.
Era comes with a set of best practices and considerations for where you might run into different behaviours than when interacting with Ethereum and requires some slight adjustments in your development setup.
For example, I needed to install an additional Hardhat extension and add one additional flag to my Hardhat configuration to compile the required bytecode for the chain:
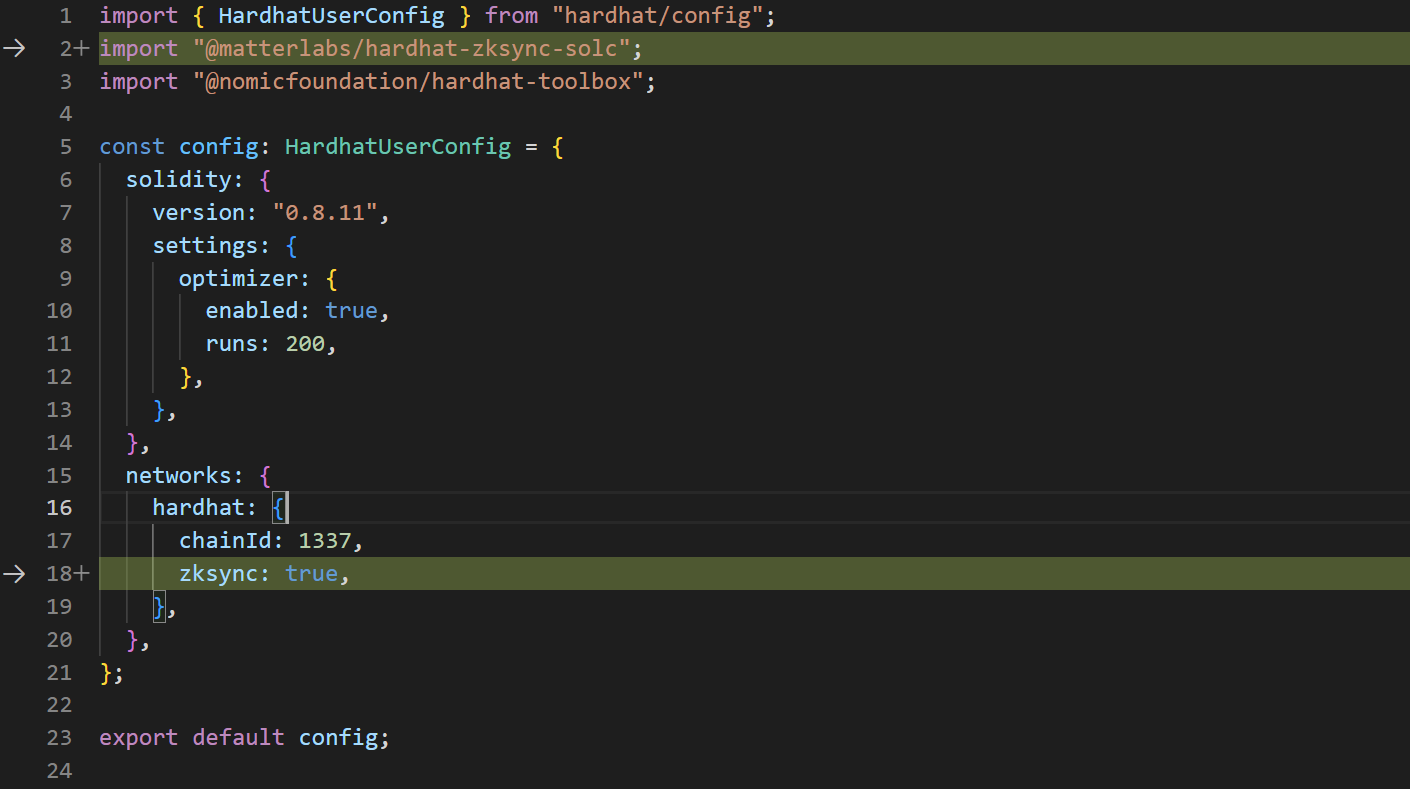
In the compilation process, the bytecode that gets generated for you to work with zkSync is different than the bytecode that gets generated by default:
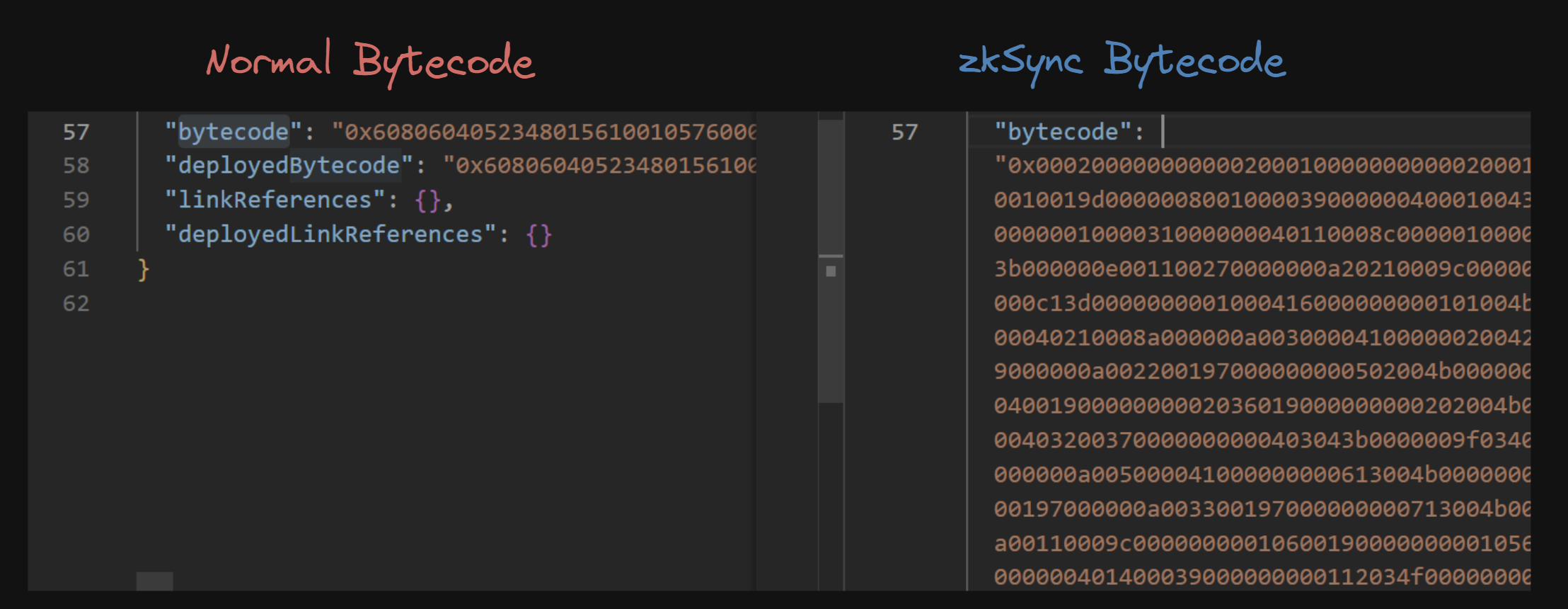
Existing deploy tooling like thirdweb deploy (used in EVM Kit) has support for this bytecode by providing the --zksync flag to the deploy command.
Overall, it's quite a small amount of changes required to use Solidity and my standard development environment to cooperate with zkSync.
Deploying to zkSync Era
Using zkSync's bridge, it's estimated about ~15 minutes for the funds to arrive on L2.

After this point, the process is the same! I'm able to deploy my Greeter smart contract, as well as my usual NFT collection with an NFT minted:
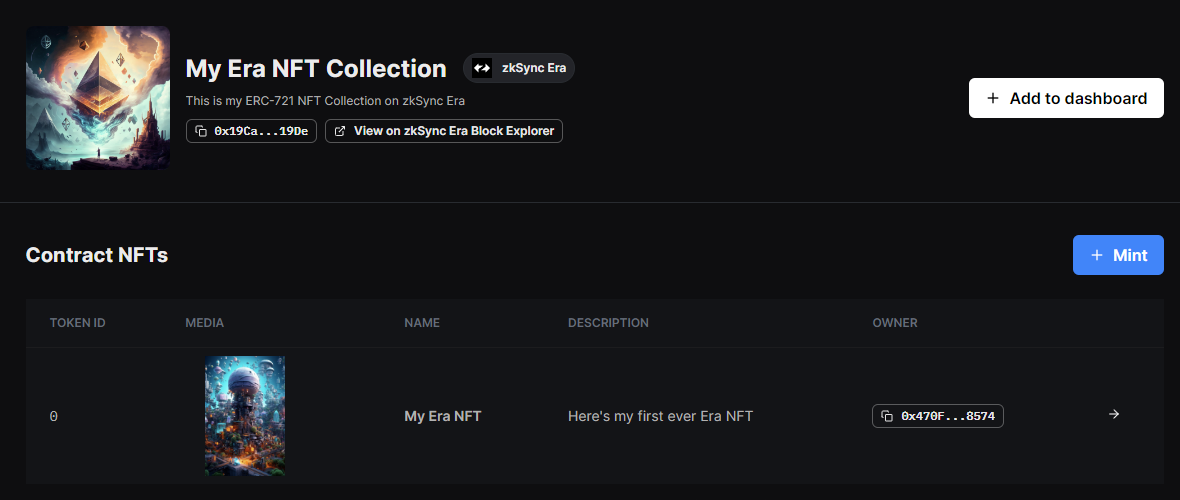
Currently, bridging funds back to Ethereum L1 from zkSync Era has a 24-hour delay:
To ensure security in the first days of the protocol, there is a 24 hour delay on withdrawals from zkSync Era (L2) to Ethereum (L1). See our blog post for more details.
Here's the summary of my interactions on zkSync Era:
| Gas Fee (in ETH) | Gas Fee (USD) | |
| Deploy Greeter Solidity smart contract | 0.001839549 | $3.47 |
| Run "setGreeting" function | 0.00007822825 | $0.15 |
| Deploy NFT Collection (via proxy) | 0.0007640925 | $1.44 |
| Mint NFT | 0.0002108245 | $0.40 |
| Bridge funds back to ETH L1 | 0.000140764 | $0.27 |
Bonus Guest: Kakarot
Just last month, a new zkEVM called Kakarot written in Cairo was announced, which aims to bring EVM compatibility to Starknet as a type 2.5 ZK-EVM, however, is considered a type 3 in its current state.

While it does has a very cool name and landing page, it also received funding from Vitalik himself, among others including Starkware.
The testnet has not yet been released but is planned to release later in 2023, and their development team has provided the following update:
The Kakarot team achieved an impressive milestone (with the support of the Starknet Foundation and the collaborative efforts of over 40 unique contributors) by implementing 100% of EVM opcodes and 8 out of 9 EVM precompiles in just six months and with less than 5,000 lines of code!
What's the future? Will One Chain Win?
Rather than it being a battle about which chain is the best, it's overall good for the improvement of Ethereum and web3 that so many different approaches are being explored; each with their own pros and cons.
Vitalik also has explained his "multi-prover theory", where rollups could potentially collaborate together to enhance the security of the whole ecosystem, among other alternatives to the future of ZK-EVMs.
Wrapping Up
That's the landscape of ZK-EVMs today, at least as I understand it!
You can find the summary below of the companies working in the space, and the types of ZK-EVM their respective products currently are:

If you're looking to build on ZK-EVMs, consider checking out my guide to creating full-stack applications on the Polygon zkEVM below:
Thanks for reading! Follow me on Twitter for more!



