A Deep Dive: How Polygon zkEVM Proves Batches of Transactions

A software engineer turned developer relations engineer in the web3 space, from Australia 🇦🇺.
In my previous post, we discussed how ZK proofs work, and how the different non-interactive ZK proofs are utilized in ZK-EVMs such as Polygon zkEVM.
But how exactly does that work? What information gets sent back to Ethereum? And how does this enable Polygon zkEVM to inherit the security of Ethereum?
In this post, we'll take a closer look at exactly what is happening under the hood, covering how transactions:
Get submitted to Polygon zkEVM.
Are executed almost instantly.
Are batched together using data encryption methods.
Get sequenced and sent to Ethereum L1.
Achieve consolidated finality on L1 with the power of ZK proofs.
Let's do this!
Submitting Transactions
As we explored in the previous post, users are constantly submitting their L2 transactions to the trusted sequencer's node via JSON-RPC interface (typically through wallets like MetaMask).
This allows the Polygon zkEVM to look and feel exactly like Ethereum from the user's perspective when interacting with dApps. Example below:
From the user's perspective, the transactions go through almost instantly, allowing them to continue using dApps immediately after submitting the transaction. This powerful UX benefit is possible because the state of the zkEVM is updated without any information being sent to Ethereum (L1) at first.
However, if users want to bridge funds from L2 (zkEVM) to L1 (Ethereum), essentially performing a withdrawal, the full transaction life-cycle needs to be complete. This requires the PolygonZkEVM smart contract to:
Receive the batches from the sequencer (know what transactions to prove).
Receive the validity proof from the aggregator (prove the transactions).
See the flow of data in a zkEVM diagram.
From the user's POV at this point, the simplified flow looks like this:
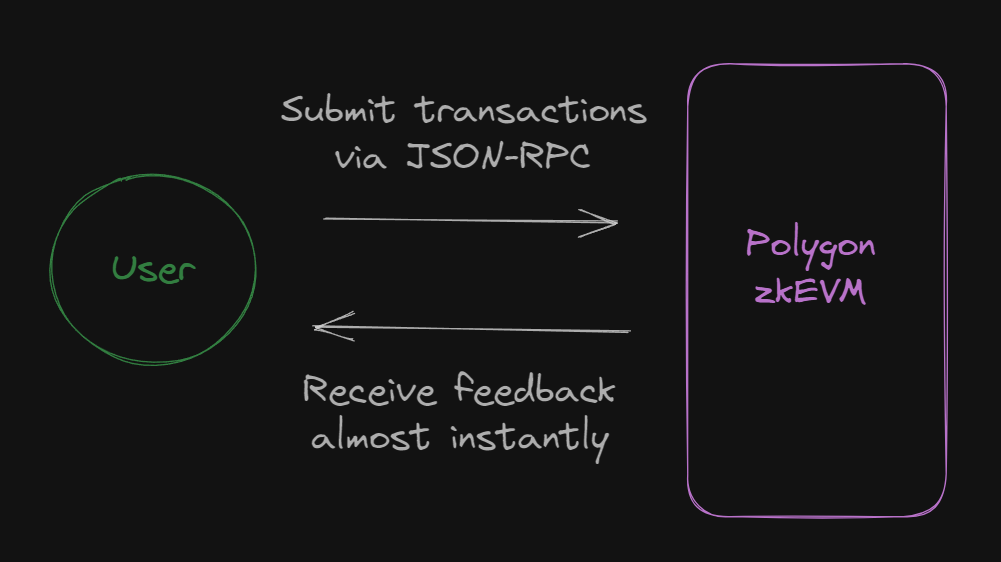
Executing Transactions
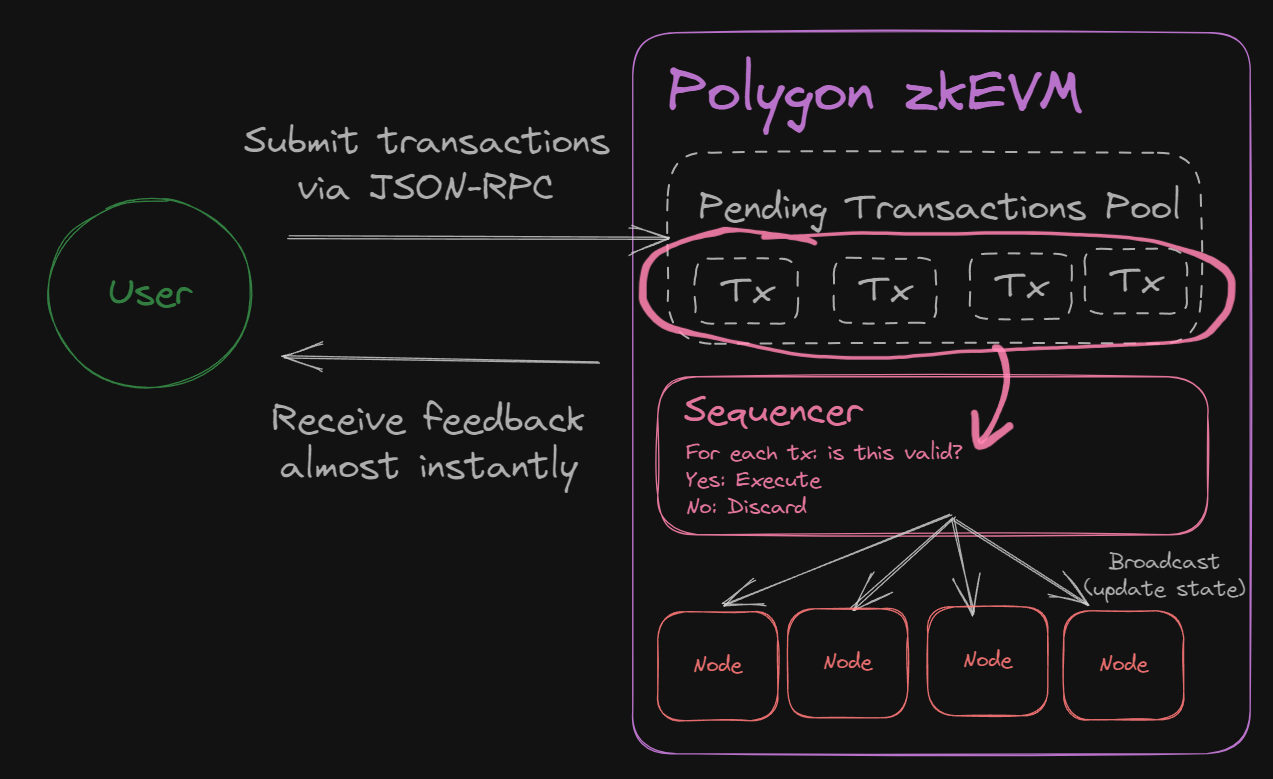
After being submitted, the transactions are stored in a pending transactions pool, where they await the sequencer's selection for either execution or discard.
The sequencer makes a few checks to see if it can discard a transaction, based on:
If the sender has enough funds to cover the transaction.
If the smart contract called exists and has valid/correct bytecode.
If the transaction isn't a duplicate.
If the transaction isn't a "double-spend", to ensure the sender's funds haven't already been spent in another transaction.
Once the transaction is considered to be valid, the sequencer updates the Polygon zkEVM state, at which point the user experiences the transaction going through almost instantly.
If we modify our diagram to explore under the hood, here's how it looks:
At this point in time, the user continues to interact with the state of the L2. Every step after this is related to posting transaction data back to Ethereum L1; which is only relevant to the user if they want to bridge funds back to Ethereum.
Batching Transactions
After being added to the L2 state, the transaction gets broadcast to all other zkEVM nodes on the network and is ready to be batched up with other transactions.
To batch transactions together, they are concatenated into a single set of bytes in binary form. On the PolygonZkEVM smart contract, a Solidity struct is defined, named BatchData.
Within this struct, a transactions field of type bytes is defined, that contains the encoded batch of transactions concatenated together.
/**
* @notice Struct which will be used to call sequenceBatches
* @param transactions L2 ethereum transactions EIP-155 or pre-EIP-155 with signature:
* EIP-155: rlp(nonce, gasprice, gasLimit, to, value, data, chainid, 0, 0,) || v || r || s
* pre-EIP-155: rlp(nonce, gasprice, gasLimit, to, value, data) || v || r || s
* @param globalExitRoot Global exit root of the batch
* @param timestamp Sequenced timestamp of the batch
* @param minForcedTimestamp Minimum timestamp of the force batch data, empty when non forced batch
*/
struct BatchData {
bytes transactions;
bytes32 globalExitRoot;
uint64 timestamp;
uint64 minForcedTimestamp;
}
As you can see in the comments above, the transactions are encoded using "RLP", and can be either EIP-155 or pre-EIP-155 transactions.
EIP-155 was a proposal created in 2016 by Vitalik to prevent replay attacks. It adds a
chainIdvalue to avoid transactions intended for one chain to also work on other chains.rlpstands for Recursive-Length Prefix Serialization. It's a data serialization method that Ethereum uses to encode the structure of any arbitrarily nested arrays of data into binary.
As for the other three fields:
globalExitRoot: The root of the global exit (Merkle) tree that stores information about asset transfers between L1 and L2. Learn more.timestamp: The time the batch was created.minForcedTimestamp: Only relevant if the user is not using the trusted sequencer (helpful for censorship resistance). Typically set to0. Learn more.
To update our diagram, let's zoom out and see what the sequencer is up to:
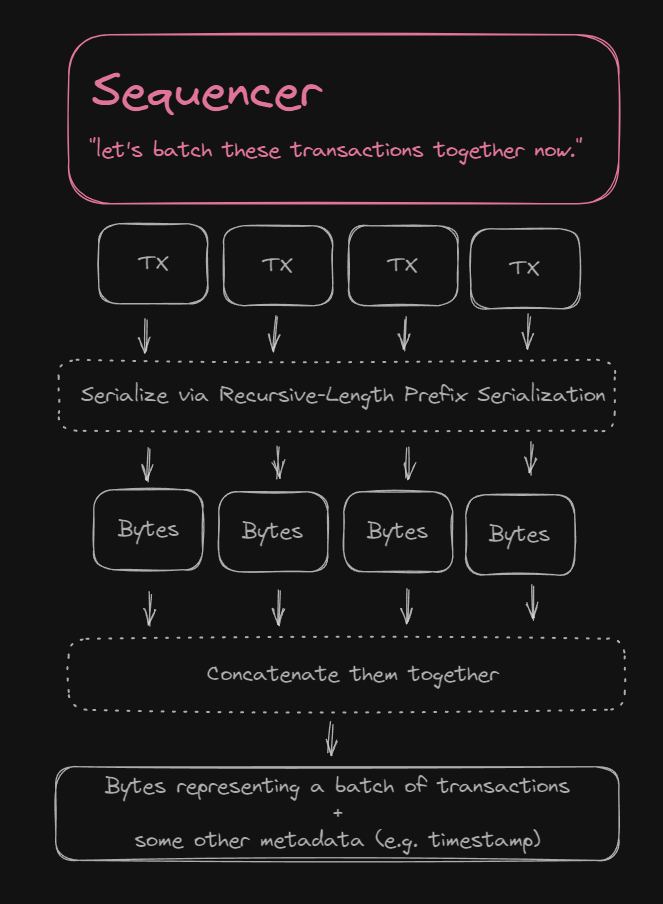
Multiple of these batches get created, according to some size rules that we'll define in the next section as defined on the L1 smart contract. So, let's see what happens with these batches next.
Sequencing Batches of Transactions
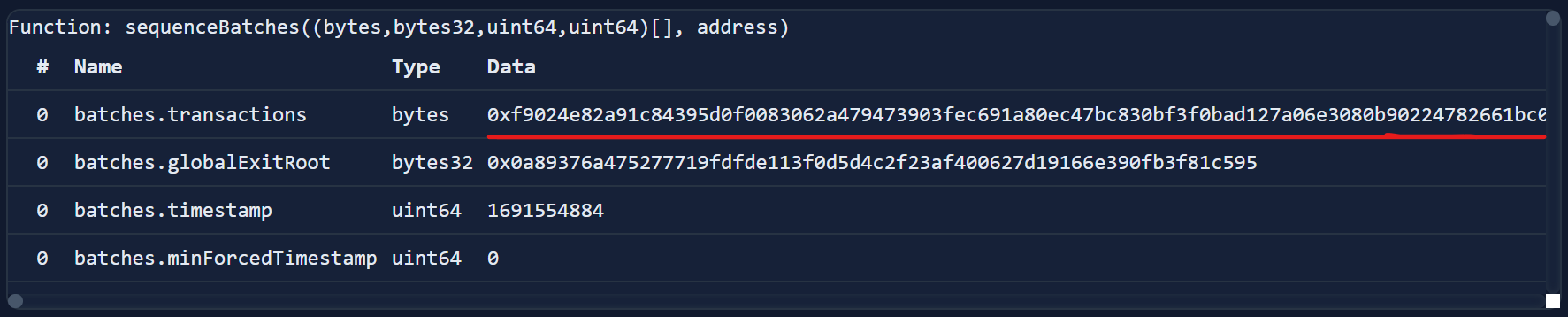
Once we have batches of transactions, they're ready to be "sequenced". To do this, the sequencer calls the PolygonZkEVM smart contract's sequenceBatches function (on L1) and provides it with multiple batches of transactions.
This transaction is an example of a sequenceBatch transaction on Ethereum mainnet. By inspecting the input data, we can see the 52 batches of transactions that got included in this particular function call:
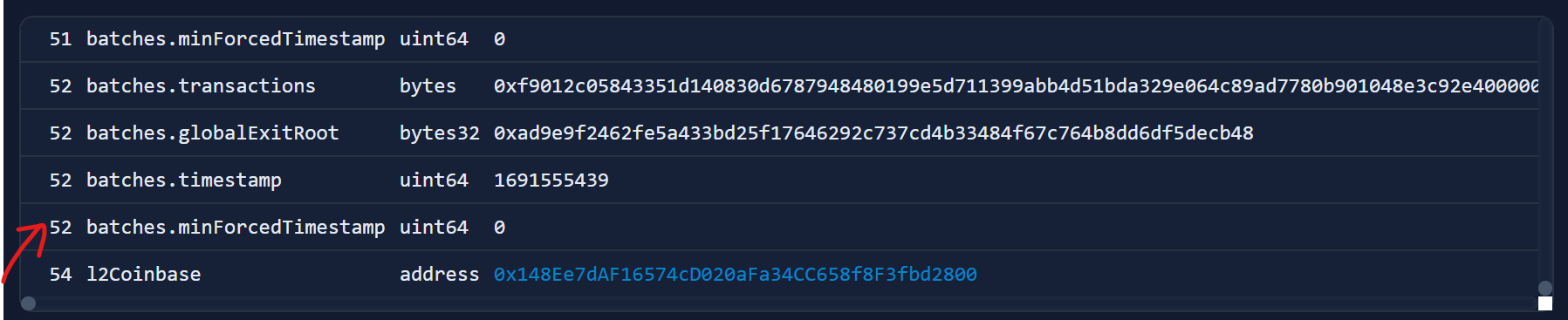
Each batch also contains the transactions field that we saw earlier (the concatenated bytes), which concatenates as many RLP encoded transactions as it can fit:
The PolygonZkEVM smart contract has a constant value called _MAX_TRANSACTIONS_BYTE_LENGTH that determines how many transactions can be concatenated together in that field. Source code:
// Max transactions bytes that can be added in a single batch
// Max keccaks circuit = (2**23 / 155286) * 44 = 2376
// Bytes per keccak = 136
// Minimum Static keccaks batch = 2
// Max bytes allowed = (2376 - 2) * 136 = 322864 bytes - 1 byte padding
// Rounded to 300000 bytes
// In order to process the transaction, the data is approximately hashed twice for ecrecover:
// 300000 bytes / 2 = 150000 bytes
// Since geth pool currently only accepts at maximum 128kb transactions:
// https://github.com/ethereum/go-ethereum/blob/master/core/txpool/txpool.go#L54
// We will limit this length to be compliant with the geth restrictions since our node will use it
// We let 8kb as a sanity margin
uint256 internal constant _MAX_TRANSACTIONS_BYTE_LENGTH = 120000;
Similarly, there is a limit to how many batches can be sent as one transaction too, in a constant variable called _MAX_VERIFY_BATCHES. Source code:
// Maximum batches that can be verified in one call. It depends on our current metrics
// This should be a protection against someone that tries to generate huge chunk of invalid batches, and we can't prove otherwise before the pending timeout expires
uint64 internal constant _MAX_VERIFY_BATCHES = 1000;
These batches are provided into a function called sequenceBatches, which accepts:
An array of
BatchDatastructs calledbatches.An address that fees for sequencing batches are sent called
l2Coinbase.
function sequenceBatches(
BatchData[] calldata batches,
address l2Coinbase
) external ifNotEmergencyState onlyTrustedSequencer {
...
}
This function iterates over each batch and ensures they are valid, before updating the virtual state on the L1 smart contract inside a mapping called sequencedBatches:
// Queue of batches that defines the virtual state
// SequenceBatchNum --> SequencedBatchData
mapping(uint64 => SequencedBatchData) public sequencedBatches;
In our diagram, here's where we are at:

The Three Finality States
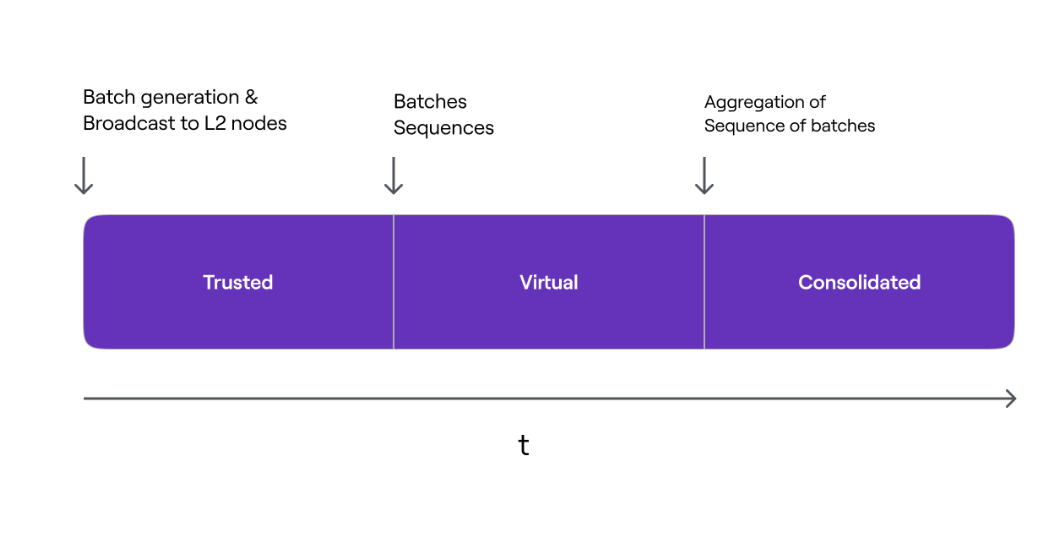
Now's a good time to introduce the different states a transaction can be in in the Polygon zkEVM. There are different phases of finality that transactions go through:
Trusted State: The state is updated on L2. Has not yet reached L1.
- Most of the time, this is what state users interact with.
Virtual State: Batches have been sequenced and data is available on L1.
- At this point, data is available on L1 for anyone to prove, but is not yet proven.
Consolidated State: A ZK proof has been posted on L1.
- At this point, the data is proven and inherits Ethereum's security.
So far, we've talked about the process up to trusted and virtual states, so let's jump into the final phase now, where ZK proofs of computational integrity are submitted to L1.
Aggregating Sequenced Batches
Once all of the sequenced batches have reached L1, the final step is to generate a ZK proof that verifies the validity of these transactions.
Aggregator nodes take the sequenced batches and provide them to the ZK prover, which produces a final SNARK using fflonk protocol. (Quick summary below):
The end result is the aggregator receives a ZK proof that is succinct enough that it can be stored on the Ethereum L1. A simplified diagram of this flow is below:

Once the aggregator node has the proof, it calls the PolygonZkEVM smart contract's verifyBatchesTrustedAggregator function, providing the proof it just received to the function, among other parameters, source code:
/**
* @notice Allows an aggregator to verify multiple batches
* @param pendingStateNum Init pending state, 0 if consolidated state is used
* @param initNumBatch Batch which the aggregator starts the verification
* @param finalNewBatch Last batch aggregator intends to verify
* @param newLocalExitRoot New local exit root once the batch is processed
* @param newStateRoot New State root once the batch is processed
* @param proof fflonk proof
*/
function verifyBatchesTrustedAggregator(
uint64 pendingStateNum,
uint64 initNumBatch,
uint64 finalNewBatch,
bytes32 newLocalExitRoot,
bytes32 newStateRoot,
bytes calldata proof
) external onlyTrustedAggregator {
...
}
Let's inspect an example transaction again to see how this looks in the real world.
This transaction comes from the trusted aggregator and calls the verifyBatchesTrustedAggregator on the PolygonZkEVM smart contract with the proof:

Details on the other parameters can be found here.
Within this function, another contract called the rollupVerifier has a function verifyProof that gets called. This function is provided with the proof as well as an inputSnark; which is a cryptographic representation of all the L2 transactions of a specific L2 State transition.
// Verify proof
if (!rollupVerifier.verifyProof(proof, [inputSnark])) {
revert InvalidProof();
}
If the proof is valid, various states are updated like the global exit root and the batchNumToStateRoot mapping containing the consolidated L2 state roots:
// State root mapping
// BatchNum --> state root
mapping(uint64 => bytes32) public batchNumToStateRoot;
Posting and verifying this proof on L1, in this example, took ~350K gas:

With one final update to our diagram, we have achieved a consolidated state on L1!

At this point, the batches of transactions are in the final "consolidated" state, and this is how Polygon zkEVM inherits the security of Ethereum; by posting and proving all transaction data back to Ethereum L1.
Wrapping Up
When interacting with the Polygon zkEVM from a user perspective, transactions are confirmed almost instantaneously, while simultaneously inheriting the security of Ethereum as this entire process occurs under the hood.
This approach provides the best of both worlds, where users have both low gas fees and fast transaction speeds within seconds and can also bridge funds back to Ethereum within ~1 hour using the power of ZK proofs.
In this blog, we've covered the full life cycle of a transaction from the Polygon zkEVM, all the way through to being proved using zero-knowledge on Ethereum L1.
If you enjoyed this content, consider giving me a follow on Twitter!



