The Ultimate Guide to Sequencers in L2 Blockchains

A software engineer turned developer relations engineer in the web3 space, from Australia 🇦🇺.
As part of Ethereum's rollup-centric roadmap, rollups are taking away the heavy lifting from Ethereum and scaling its throughput by orders of magnitude, reflected in the $20B+ TVL stored in L2 chains today.
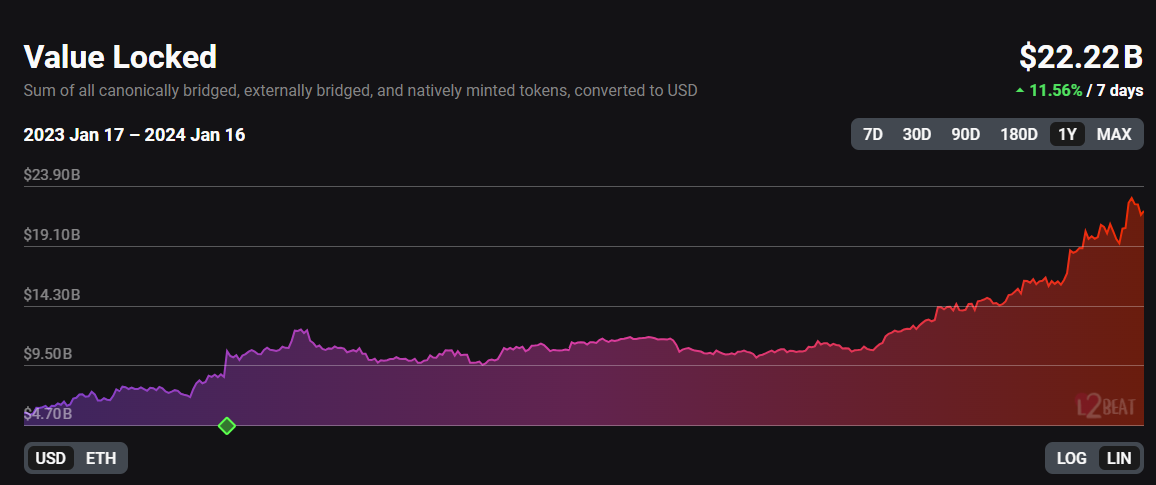
But, with great power, comes great responsibility, and with the blockchain trilemma in mind, these L2 scalability gains currently come at the cost of weaker decentralization and security, along with added complexity.
In this post, we'll cover a key component of rollups called sequencers, how they work, the pros and cons of different kinds of sequencers, and finally explore a relatively new concept called shared sequencers. Let's dive in.
What is a Sequencer?
If you clicked on this post I'm going to assume you're already familiar with L2s, rollups, sequencers, and all the rest. But just so we're on the same page, let's do a quick definition of what we're talking about here.
If you're interested in a deep dive into a specific L2 and each of its components, check out my previous blog on zkEVMs:
Rollups consist of several components. While each of them is slightly different, each of them shares key components, such as the:
Sequencer: Picks up transactions from the L2 mempool, decides whether to execute or discard them and broadcasts this information to other nodes.
Layer 1 Rollup Contract: A smart contract living on Ethereum, that receives batches of transaction data that occurred on L2. It also receives proofs (either fault proofs for optimistic rollups, or ZK proofs for ZK rollups) to verify batches.
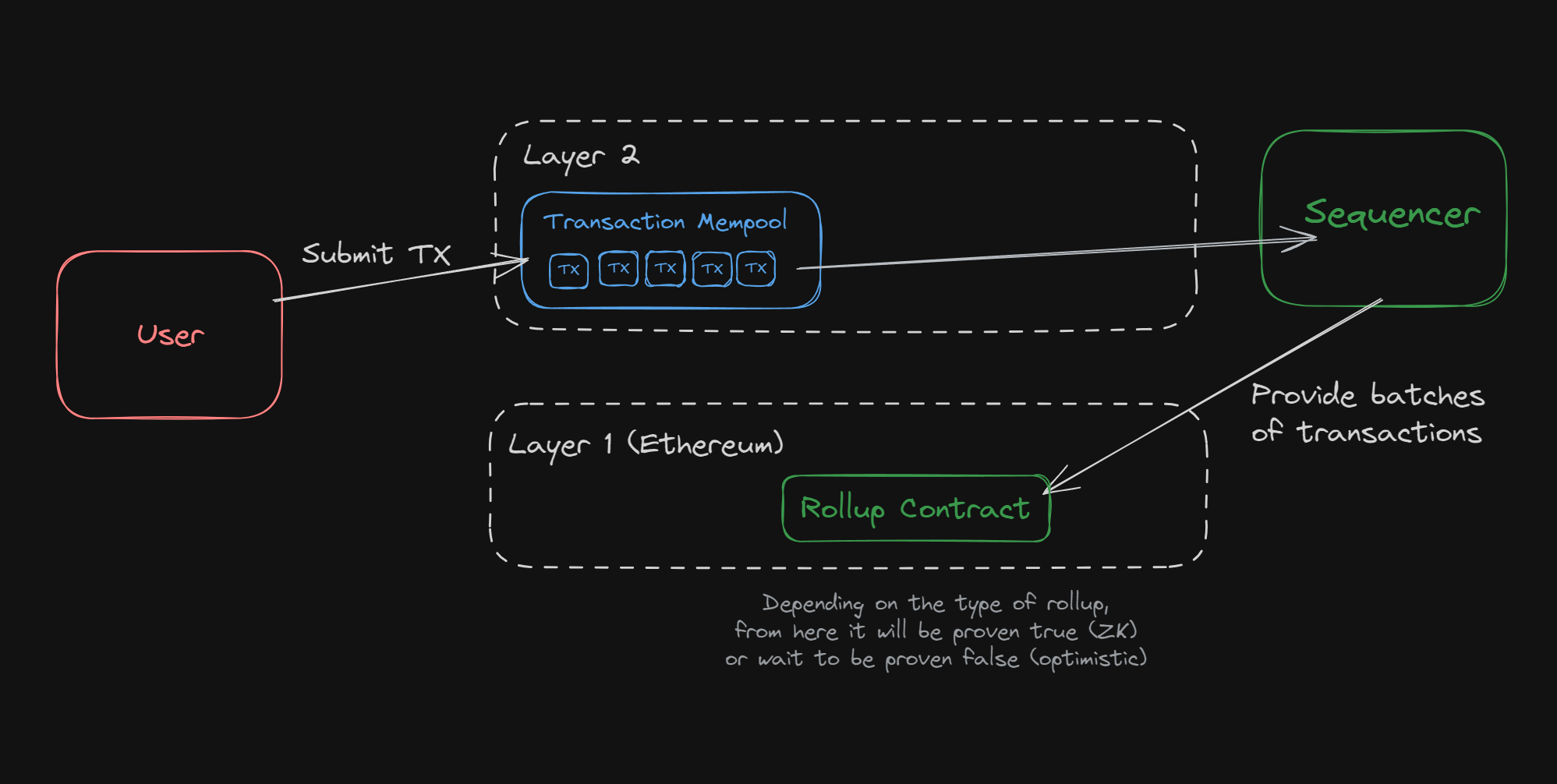
The above diagram is a simplified version of a rollup's architecture. At a high level, it's how rollups operate; arguably the most important component of the entire system is the sequencer, because of its two critical responsibilities:
Read transactions from the mempool and execute or discard them. Without the sequencer, none of the rollup's transactions would be handled at all.
Batch transactions up together, and ship them to Ethereum. Without the sequencer, there would be no "rolling up"; it is responsible for sending all of the transaction data that occurred on L2 to Ethereum.
Next, let's look closer at how these sequencers work in today's rollup landscape.
Different Kinds of Sequencers
Sequencers come in different shapes and sizes. Each rollup (Polygon zkEVM, Linea, Base, Optimism, etc.) utilizes its own unique sequencer. In this section, we're going to explore the different implementations of sequencers that exist today.
Centralized Sequencers
Centralized sequencers are the most common kind of sequencer that rollups use today. They're used by Optimism, Abritrum One, Base, zkSync Era, Linea, Polygon zkEVM, Scroll, and more.
To simplify things, a centralized sequence is software that fetches transactions from the mempool, checks if they're valid, and then puts valid ones into a batch to send to Ethereum. This type of sequencer is labelled "centralized" because it:
Is usually maintained by the core devs of the rollup team
Likely operates on a centralized server
Uses a single account to post batches to Ethereum
The Benefits of Centralized Sequencers
Unlike blockchains or other decentralized systems, a centralized sequencer's only real concern is the efficiency of its software, and the hardware it's running on; it has no concern for how decentralized it is.
While "centralized" comes with negative connotations, a centralized sequencer provides the highest performance by providing users near-instant finality at the L2 level in a consistent manner and reliably submitting valid batches of transactions to Ethereum.
This arguably provides the best experience for users. It provides the fastest way to approve user transactions (which is a high priority for most people) and enables users to withdraw their funds more quickly from L2s in the case of zkEVMs; as the batches submitted by the trusted sequencer are likely going to be valid ones.
While centralized sequencers may provide a great UX, some people believe it undermines the benefits of building decentralized applications. If such an important component is centralized, then why even use a decentralized system in the first place?
The Downsides to Centralized Sequencers
With high scalability, comes the delicate balancing of decentralization and security, or something like that... As you can imagine, maxing out your scalability skill leaves you vulnerable to other downsides.
If a centralized sequencer goes down, the rollup effectively stops doing its job entirely. It stops handling transactions from users on the L2 and also stops sending batch data back to Ethereum.
This isn't a wild "what if" scenario either. This happened recently during the Inscriptions craze on Arbitrum's L2. The sequencer "stalled", and the network suffered 78 minutes of downtime because of the centralized sequencer setup.
In addition, because the centralized sequencer handles all of a rollup's transactions, it's up to the centralized sequencer to determine what MEV is extracted and in what ways it benefits itself with the information of these incoming transactions (such as frontrunning for example).
With this level of power, you might also wonder what's stopping a sequencer from censoring transactions it doesn't want to go through. Most rollups have a mechanism that allows users to bypass the sequencer and "force" their transaction, however, at this point, these mechanisms are often disabled while the systems mature.
Decentralized Sequencers
The distinction between centralized sequencers and decentralized sequencers is comparable to centralized networks and decentralized ones like blockchains (which you've probably heard thousands of times by now).
As the name suggests, a decentralized sequencer uses a decentralized network of nodes to perform the responsibilities of the sequencer we discussed in the previous section.
An example of a layer 2 blockchain that implements a decentralized pool of sequencer nodes is Metis. Metis implements this by tapping into its existing decentralized P2P validators and block producer network and randomly selecting and rotating what sequencer node performs these responsibilities.
Without being too verbose, this essentially has the reverse effects of centralized sequencers. Where centralized sequencers shine is where decentralized sequencers lack, and vice versa.
It is more time-consuming, less consistent, and likely more expensive to call upon a decentralized network of nodes to act as a sequencer, but does not have the single point of failure that centralized sequencers do.
Shared Sequencers
Shared sequencers such as Espresso and Astria allow multiple rollups to share a single decentralized network of sequencers.
Shared sequencers are a network that sits in the middle between L2 and Ethereum L1 that anyone can permissionlessly utilize as a decentralized sequencer for their rollup. They're almost like a decentralized sequencer as a service.
A key differentiator here between decentralized sequencers and shared sequencers is that shared sequencers serve multiple blockchains rather than just one and shared sequencers are actually blockchain networks themselves.
For example, the Astria Shared Sequencer describes itself as "a decentralized network of nodes utilizing CometBFT that come to a consensus on an ordered set of transactions (ie. it is a blockchain)". Source ↗
A key selling point for shared sequencers is that they introduce interoperability advantages between rollups, providing additional value to users using rollups that opt-in to a decentralized shared sequencing layer.
For example, Espresso describes how users can express atomic dependencies between transactions across different rollups, enabling many new use cases such as cross-rollup DEX arbitrage.
Based Rollups
Rollups such as Taiko are implementing an alternative strategy for decentralized sequencing which Justin Drake coined "based" (not to be confused with the Base rollup) in this post.
Based rollups or L1-sequenced rollups utilize Ethereum's decentralization by rolling up multiple transactions off-chain (as any L2 does) and sending them as a single transaction to Ethereum.
Imagine decentralized sequencing, but instead of a separate blockchain, it relies just uses Ethereum to handle both the secure recording of transaction data and the enforcement of consensus rules.
The downside to this approach is that most of the limitations that the L1 has, such as transaction confirmation delays (with caveats via restaking), block times, transaction ordering, and data availability throughput are all inherited as limitations in the based rollup.
So, What's The Best...?
TLDR: It's up to you. As either a user or developer (or both), you're going to have different preferences from others.
Some developers want their users to have the fast experiences that rollups like Base or Polygon zkEVM currently offer by utilizing centralized sequencers, whereas others may prefer to have stronger decentralization at the cost of speed.
In general, my opinion is that we're always going to see a trend where these solutions start by sacrificing decentralization for performance, and then over time become more decentralized while maintaining that level of performance. This is true more broadly in web3 than for just sequencers too.
It's valuable to know the tradeoffs that are being made to power your experience in the L2 world and make your own decisions based on your preferences.
Want more content like this?
I usually post stuff like this on my Twitter first. If you enjoyed this content check out my Twitter @jarrodwattsdev for more educational web3 content.


